
문자열 인코딩 종류(Character Encoding)
Updated:
흔히 우리는 “문자가 깨졌다”는 표현을 많이 쓴다. 이 말을 정확히 하면 “문자열의 인코딩 방식과 디코딩 방식이 다르다”는 말이다. 문자열의 인코딩이란 무엇일까? 문자열 인코딩 종류에는 어떤 것들이 있을까?
- 문자열 인코딩 디코딩이란?
- 문자열 인코딩 종류
- 참고
1. 문자열 인코딩 디코딩이란?
컴퓨터는 문자를 인식할 수 없기 때문에 숫자로 변환되어 저장됩니다. 변환해주기 위해서는 기준이 있어야하는데 이것을 문자 코드라고 하며 대표적으로 ASCII코드 또는 유니코드가 있습니다.
이렇게 문자 코드를 기준으로 문자를 코드로 변환하는 것을 문자 인코딩(encoding) 이라하고 코드를 문자로 변환하는 것을 문자 디코딩(decoding) 이라고 합니다.
인코딩/디코딩은 정보의 형태나 형식을 변환하는 처리에 대해 표준화하고 보안, 처리 속도 향상, 저장 공간 절약 등의 목적으로 사용합니다.
이렇게 문자 코드를 기준으로 문자를 코드로 변환하는 것을 문자 인코딩(encoding) 이라하고 코드를 문자로 변환하는 것을 문자 디코딩(decoding) 이라고 합니다.
인코딩/디코딩은 정보의 형태나 형식을 변환하는 처리에 대해 표준화하고 보안, 처리 속도 향상, 저장 공간 절약 등의 목적으로 사용합니다.
2. 문자열 인코딩 종류
2.1. ASCII
- American Standard Code for Information Interchange)
- 128개의 문자,
영어만표현 가능
2.2. ANSI
- American National Standard Institute
- 특정 인코딩 방식이 아니라 시스템 기본 코드 페이지를 의미 “default local/codepage for my system”
- officially called “Windows code pages”
- 언어별로 다른 Code Page 사용하며
다양한 언어표현 가능 - 예시
EUC-KR- ASCII range는 1byte, 한글은 2bytes로 표현하는 가변 길이 인코딩 방식
CP949(Codepage 949, MS949, Windows-949)- Microsoft에서 만든
EUC-KR확장 - EUC-KR 에서 지원되는 한글 2350자 외에 나머지 8822자가 추가되었으며 Win95 한글판에 탑재되어 배포됨.
- Microsoft에서 만든
2.3. Unicode
- Unicode Transformation Format
- 다양한 언어의
모든 문자표현 가능 - 예시
UTF-8- 하나의 문자를 1~4바이트의 가변길이로 표현. 1바이트 영역은 ASCII코드와 하위 호환되며 ASCII코드의 128개 문자 집합은 UTF-8과 동일하게 호환됨. 현재 인터넷에서 가장 많이 쓰이는 인코딩이며 뛰어난 크로스플랫폼 호환성도 갖고 있음.
UTF-16- 모든 문자를 2바이트의 고정크기로 표현하고 UTF-8과 마찬가지로 ACII코드의 128개 문자 집합에 대해 호환성을 가짐. 바이트 순서가 정해지지 않아 리틀/빅 엔디안 문제가 발생하기 때문에 인터넷 상에서의 사용을 권고하지 않음. (Java와 .NET Framework의 기본 인코딩.)
2.4. Percent(%) Encoding
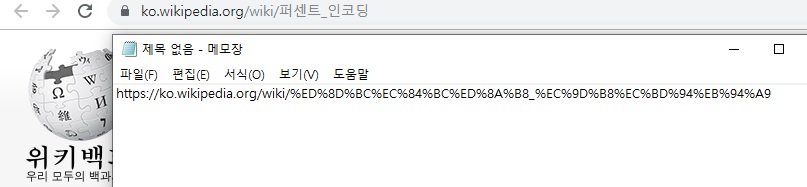
URL에 문자를 표현- URL을 메모장에 복사할 때 깨지는 이유
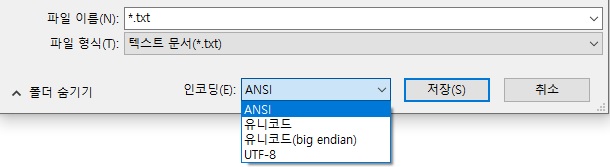
- URL의 문자열 인코딩은 Percent Encoding 인데 반해, 메모장의 문자열 인코딩은 ANSI Encoding(윈도우 처음 설치 시 언어를 한글로 선택하면 기본 인코딩 방식이 CP949로 설정된다.)으로, 문자열 인코딩이 다르기 때문이다.
3. 참고
문자열 인코딩 개념 정리(ASCII/ANSI/EUC-KR/CP949/UTF-8/UNICODE)
Comments